3. create_chatbot_model.py - 감정 인식 모델 만들기
2023. 12. 9. 20:13ㆍ개인 프로젝트/📚 감정 인식 및 MBTI 분석 ChatBot
1. create_chatbot_model.py
# 필요한 모듈 임포트
import os
os.environ["TF_CPP_MIN_LOG_LEVEL"] = "2" # CPU버전
import pandas as pd
import tensorflow as tf
from tensorflow.keras import preprocessing
from tensorflow.keras.models import Model
from tensorflow.keras.layers import (
Input,
Embedding,
Dense,
Dropout,
Conv1D,
GlobalMaxPool1D,
concatenate,
)
# 1 데이터 읽어 오기
train_file = "chatbot_data.csv"
data = pd.read_csv(train_file, delimiter=",")
features = data["Q"].tolist()
labels = data["label"].tolist()
# 2 단어 인덱스 시퀀스 벡터
corpus = [preprocessing.text.text_to_word_sequence(text) for text in features]
tokenizer = preprocessing.text.Tokenizer()
tokenizer.fit_on_texts(corpus)
sequences = tokenizer.texts_to_sequences(corpus)
word_index = tokenizer.word_index
MAX_SEQ_LEN = 15
padded_seqs = preprocessing.sequence.pad_sequences(
sequences, maxlen=MAX_SEQ_LEN, padding="post"
)
# 3 학습용, 검증용, 테스트용으로 데이터셋 생성
# 학습:검증:테스트 = 7:2:1
ds = tf.data.Dataset.from_tensor_slices((padded_seqs, labels))
ds = ds.shuffle(len(features))
train_size = int(len(padded_seqs) * 0.7)
val_size = int(len(padded_seqs) * 0.2)
test_size = int(len(padded_seqs) * 0.1)
train_ds = ds.take(train_size).batch(20)
val_ds = ds.skip(train_size).take(val_size).batch(20)
test_ds = ds.skip(train_size + val_size).take(test_size).batch(20)
# 하이퍼파라미터 설정
dropout_prob = 0.5
EMB_SIZE = 128
EPOCH = 5
VOCAB_SIZE = len(word_index) + 1
# 4 CNN 모델 정의
input_layer = Input(shape=(MAX_SEQ_LEN,))
embedding_layer = Embedding(VOCAB_SIZE, EMB_SIZE, input_length=MAX_SEQ_LEN)(input_layer)
dropout_emb = Dropout(rate=dropout_prob)(embedding_layer)
conv1 = Conv1D(filters=128, kernel_size=3, padding="valid", activation=tf.nn.relu)(
dropout_emb
)
pool1 = GlobalMaxPool1D()(conv1)
conv2 = Conv1D(filters=128, kernel_size=4, padding="valid", activation=tf.nn.relu)(
dropout_emb
)
pool2 = GlobalMaxPool1D()(conv2)
conv3 = Conv1D(filters=128, kernel_size=5, padding="valid", activation=tf.nn.relu)(
dropout_emb
)
pool3 = GlobalMaxPool1D()(conv3)
# 3,4,5-gram 이후 합치기
concat = concatenate([pool1, pool2, pool3])
hidden = Dense(128, activation=tf.nn.relu)(concat)
dropout_hidden = Dropout(rate=dropout_prob)(hidden)
logits = Dense(3, name="logits")(dropout_hidden)
predictions = Dense(3, activation=tf.nn.softmax)(logits)
# 5 모델 생성
model = Model(inputs=input_layer, outputs=predictions)
model.compile(
optimizer="adam", loss="sparse_categorical_crossentropy", metrics=["accuracy"]
)
# 6 모델 학습
model.fit(train_ds, validation_data=val_ds, epochs=EPOCH, verbose=1)
# 7모델 평가(테스트 데이터셋 이용)
loss, accuracy = model.evaluate(test_ds, verbose=1)
print("Acc : %f" % (accuracy * 100))
print("Loss : %f" % (loss))
# 8 모델 저장
model.save("cnn_model.keras")
1) 감정 인식에 사용한 우리말뭉치
GitHub - songys/Chatbot_data: Chatbot_data_for_Korean
Chatbot_data_for_Korean. Contribute to songys/Chatbot_data development by creating an account on GitHub.
github.com
2) 사용 교재

GitHub - keiraydev/chatbot: 한빛미디어 처음 배우는 딥러닝 챗봇
한빛미디어 처음 배우는 딥러닝 챗봇. Contribute to keiraydev/chatbot development by creating an account on GitHub.
github.com
2. 코드 세부 설명
먼저 말뭉치와 관련된 설명은 원천 깃허브에 설명이 되어있으므로 생략하겠습니다.
# 필요한 모듈 임포트
import os
os.environ["TF_CPP_MIN_LOG_LEVEL"] = "2" # CPU버전
import pandas as pd
import tensorflow as tf
from tensorflow.keras import preprocessing
from tensorflow.keras.models import Model
from tensorflow.keras.layers import (
Input,
Embedding,
Dense,
Dropout,
Conv1D,
GlobalMaxPool1D,
concatenate,
)당시 GPU 환경 설정을 하지 않았기 때문에 CPU로 진행했습니다.
# 1 데이터 읽어 오기
train_file = "chatbot_data.csv"
data = pd.read_csv(train_file, delimiter=",")
features = data["Q"].tolist()
labels = data["label"].tolist()말뭉치 데이터인 chatbot_data.csv 를 읽어옵니다.
# 2 단어 인덱스 시퀀스 벡터
corpus = [preprocessing.text.text_to_word_sequence(text) for text in features]
tokenizer = preprocessing.text.Tokenizer()
tokenizer.fit_on_texts(corpus)
sequences = tokenizer.texts_to_sequences(corpus)
word_index = tokenizer.word_index
MAX_SEQ_LEN = 15
padded_seqs = preprocessing.sequence.pad_sequences(
sequences, maxlen=MAX_SEQ_LEN, padding="post"
)
# 3 학습용, 검증용, 테스트용으로 데이터셋 생성
# 학습:검증:테스트 = 7:2:1
ds = tf.data.Dataset.from_tensor_slices((padded_seqs, labels))
ds = ds.shuffle(len(features))
train_size = int(len(padded_seqs) * 0.7)
val_size = int(len(padded_seqs) * 0.2)
test_size = int(len(padded_seqs) * 0.1)
train_ds = ds.take(train_size).batch(20)
val_ds = ds.skip(train_size).take(val_size).batch(20)
test_ds = ds.skip(train_size + val_size).take(test_size).batch(20)
# 하이퍼파라미터 설정
dropout_prob = 0.5
EMB_SIZE = 128
EPOCH = 5
VOCAB_SIZE = len(word_index) + 1
# 4 CNN 모델 정의
input_layer = Input(shape=(MAX_SEQ_LEN,))
embedding_layer = Embedding(VOCAB_SIZE, EMB_SIZE, input_length=MAX_SEQ_LEN)(input_layer)
dropout_emb = Dropout(rate=dropout_prob)(embedding_layer)
conv1 = Conv1D(filters=128, kernel_size=3, padding="valid", activation=tf.nn.relu)(
dropout_emb
)
pool1 = GlobalMaxPool1D()(conv1)
conv2 = Conv1D(filters=128, kernel_size=4, padding="valid", activation=tf.nn.relu)(
dropout_emb
)
pool2 = GlobalMaxPool1D()(conv2)
conv3 = Conv1D(filters=128, kernel_size=5, padding="valid", activation=tf.nn.relu)(
dropout_emb
)
pool3 = GlobalMaxPool1D()(conv3)
# 3,4,5-gram 이후 합치기
concat = concatenate([pool1, pool2, pool3])
hidden = Dense(128, activation=tf.nn.relu)(concat)
dropout_hidden = Dropout(rate=dropout_prob)(hidden)
logits = Dense(3, name="logits")(dropout_hidden)
predictions = Dense(3, activation=tf.nn.softmax)(logits)
# 5 모델 생성
model = Model(inputs=input_layer, outputs=predictions)
model.compile(
optimizer="adam", loss="sparse_categorical_crossentropy", metrics=["accuracy"]
)학습을 진행하기 전의 준비 과정입니다. 코드의 epoch는 5입니다.
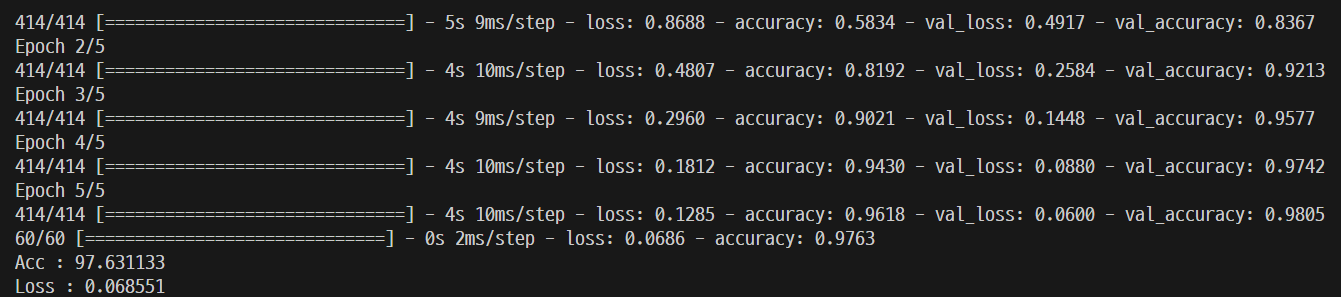
# 6 모델 학습
model.fit(train_ds, validation_data=val_ds, epochs=EPOCH, verbose=1)
# 7모델 평가(테스트 데이터셋 이용)
loss, accuracy = model.evaluate(test_ds, verbose=1)
print("Acc : %f" % (accuracy * 100))
print("Loss : %f" % (loss))
# 8 모델 저장
model.save("cnn_model.keras")실제로 학습을 진행한 뒤에 .keras 파일로 저장합니다.


'개인 프로젝트 > 📚 감정 인식 및 MBTI 분석 ChatBot' 카테고리의 다른 글
| 6. 구름IDE.py - 실제 서버 구동 파일 (0) | 2023.12.10 |
|---|---|
| 5. main.py - 알고리즘 테스트 파일 (0) | 2023.12.10 |
| 4. NaverAPIIDPW.py - 네이버 API 정보 (0) | 2023.12.09 |
| 2. CorpusExtraction.py - 크롤링 정보 가공 (0) | 2023.12.09 |
| 1. Crawling_origin.r - MBTI 갤러리 크롤링 (0) | 2023.12.09 |
 5. main.py - 알고리즘 테스트 파일
5. main.py - 알고리즘 테스트 파일