import json
import datetime
import matplotlib.pyplot as plt
import matplotlib.font_manager as fm
import os
def run(input_file, group_name, font_path, result_folder):
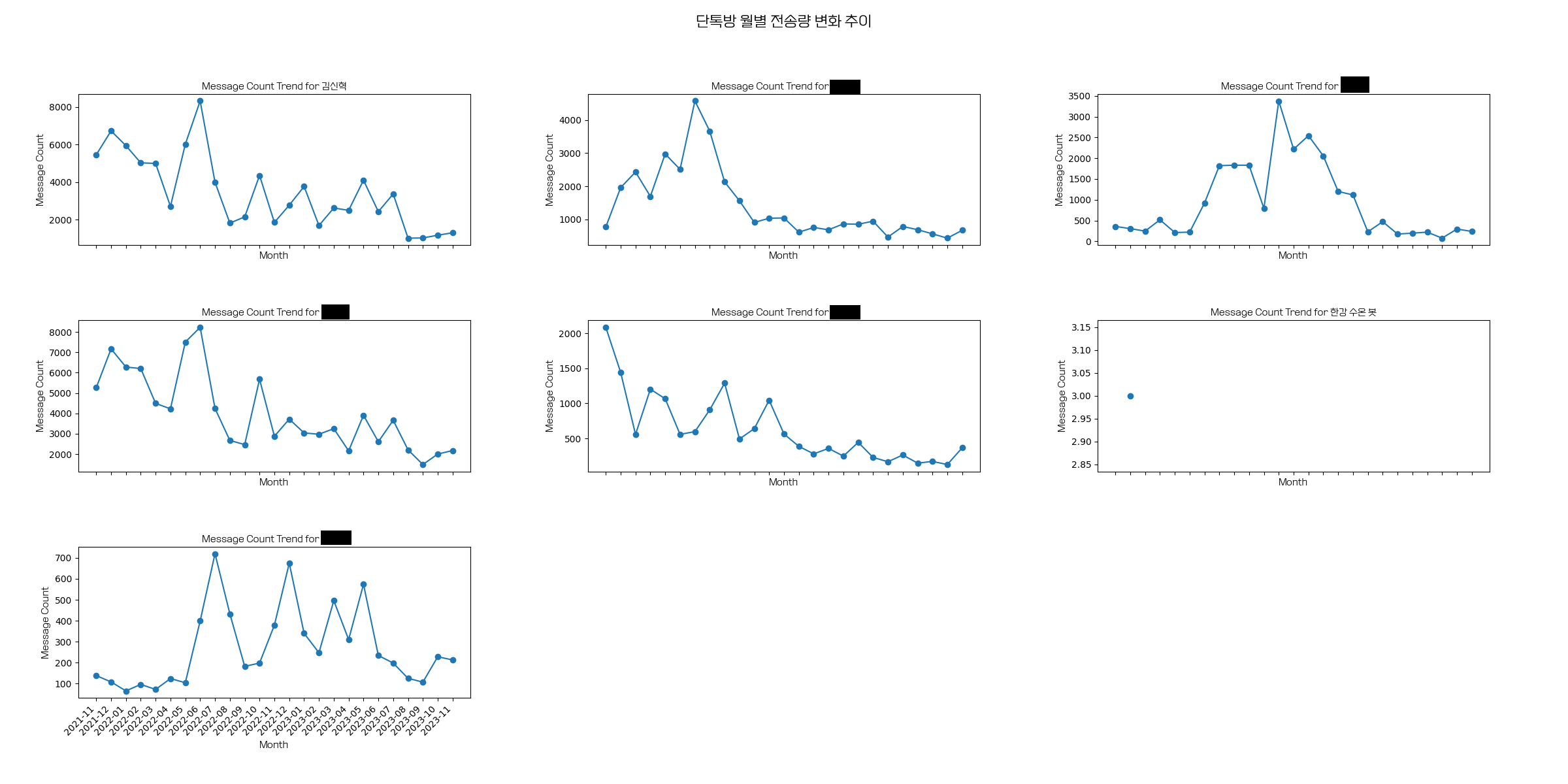
ChartTitle = group_name + " 월별 전송량 변화 추이"
# 폰트 설정
fontprop = fm.FontProperties(fname=font_path)
# JSON 파일 읽기
with open(input_file, "r", encoding="utf-8") as f:
json_data = json.load(f)
# 사용자 목록 추출
user_list = list(set(item.get("name") for item in json_data if item.get("name")))
# 그래프 영역 설정
num_users = len(user_list)
num_cols = 3 # 한 줄에 표시할 그래프의 수
num_rows = (num_users + num_cols - 1) // num_cols # 필요한 행의 수
fig, axes = plt.subplots(num_rows, num_cols, figsize=(24, 4 * num_rows), sharex=True)
fig.suptitle(ChartTitle, fontsize=16, fontproperties=fontprop)
# 각 사용자별 월별 메시지 전송량 추이 그래프 그리기
for i, target_user in enumerate(user_list):
target_name = target_user
row = i // num_cols # 현재 그래프의 행 인덱스
col = i % num_cols # 현재 그래프의 열 인덱스
# 사용자별 발신 시간 추출 및 처리
user_sent_counts = {}
for item in json_data:
name = item.get("name")
date_str = item.get("date")
if name and date_str:
sent_time = datetime.datetime.strptime(date_str, "%Y-%m-%dT%H:%M:%S")
if name == target_user:
year_month = sent_time.strftime("%Y-%m")
if year_month in user_sent_counts:
user_sent_counts[year_month] += 1
else:
user_sent_counts[year_month] = 1
# 월별 메시지 전송량 추이 그래프 그리기
x = sorted(user_sent_counts.keys(), key=lambda d: datetime.datetime.strptime(d, "%Y-%m")) # 월별 메시지 전송량을 정렬된 순서로 그리기 위해 정렬
y = [user_sent_counts[key] for key in x]
# 각 사용자별 그래프 그리기
ax = axes[row, col]
ax.plot(x, y, marker="o")
ax.set_xlabel("Month", fontproperties=fontprop)
ax.set_ylabel("Message Count", fontproperties=fontprop)
ax.set_title(f"Message Count Trend for {target_name}", fontproperties=fontprop)
ax.set_xticks(range(len(x)))
ax.set_xticklabels(x, rotation=45, ha="right")
# 빈 그래프 영역 제거
if num_users % num_cols != 0:
for i in range(num_users, num_rows * num_cols):
row = i // num_cols
col = i % num_cols
fig.delaxes(axes[row, col])
# 그래프 간 간격 조정
plt.subplots_adjust(left=0.05, right=0.95, hspace=0.5, wspace=0.3)
# 결과 폴더가 없다면 생성
if not os.path.exists(result_folder):
os.makedirs(result_folder)
# 이미지로 저장
plt.savefig(result_folder + ChartTitle + '.png')
# 모든 그래프 표시
plt.show()
import json
import datetime
import glob
import matplotlib.pyplot as plt
import matplotlib.font_manager as fm
import os
def run(font_path, group_name, result_folder):
start_date = input("YYYYMM: ")
if start_date == "all":
start_date = ""
ChartTitle = "모든 기간"
else:
start_year = start_date[:4]
start_month = start_date[4:]
ChartTitle = start_year + "년 " + start_month + "월"
# 폰트 설정
fontprop = fm.FontProperties(fname=font_path)
# 입력 파일 경로
input_files = glob.glob(fr".\src\data{start_date}*.json")
# 전체 사용자의 발신 시간대 정보를 저장할 딕셔너리
user_hour_counts = {}
# JSON 파일 읽기
for input_file in input_files:
with open(input_file, "r", encoding="utf-8") as f:
json_data = json.load(f)
# 사용자별 발신 시간 추출 및 처리
for item in json_data:
name = item.get("name")
date_str = item.get("date")
if name and date_str:
sent_time = datetime.datetime.strptime(date_str, "%Y-%m-%dT%H:%M:%S")
if name in user_hour_counts:
user_hour_counts[name].append(sent_time.hour)
else:
user_hour_counts[name] = [sent_time.hour]
# 개별 사용자의 발신 시간대 그래프 그리기
for name, hour_counts in user_hour_counts.items():
hour_counts_dict = {}
for hour in hour_counts:
if hour in hour_counts_dict:
hour_counts_dict[hour] += 1
else:
hour_counts_dict[hour] = 1
hours = sorted(hour_counts_dict.keys())
counts = [hour_counts_dict[hour] for hour in hours]
plt.plot(hours, counts, label=name)
plt.xlabel("Hour", fontproperties=fontprop)
plt.ylabel("Count", fontproperties=fontprop)
plt.suptitle(group_name + " 메세지 전송 시각", fontsize=16, fontproperties=fontprop)
plt.legend(prop=fontprop)
plt.title(ChartTitle + " 발신 시간: 메세지 건 수 기준", fontproperties=fontprop)
# 결과 폴더가 없다면 생성
if not os.path.exists(result_folder):
os.makedirs(result_folder)
# 이미지로 저장
plt.savefig(result_folder + ChartTitle + " " + group_name + " 메세지 전송 시각(메세지 건 수 기준).png")
plt.show()
import json
import datetime
import glob
import matplotlib.pyplot as plt
import matplotlib.font_manager as fm
import os
def run(font_path, group_name, result_folder):
# 폰트 설정
fontprop = fm.FontProperties(fname=font_path)
start_date = input("YYYYMM: ")
if start_date == "all":
start_date = ""
ChartTitle = "모든 기간"
else:
start_year = start_date[:4]
start_month = start_date[4:]
ChartTitle = start_year + "년 " + start_month + "월"
# 입력 파일 경로
input_files = glob.glob(fr".\src\data{start_date}*.json")
# 전체 사용자의 발신 시간대 정보를 저장할 딕셔너리
user_hour_counts = {}
# JSON 파일 읽기
for input_file in input_files:
with open(input_file, "r", encoding="utf-8") as f:
json_data = json.load(f)
# 사용자별 발신 시간과 메시지 길이 추출 및 처리
for item in json_data:
name = item.get("name")
date_str = item.get("date")
message_text = item.get("text")
if name and date_str and message_text:
sent_time = datetime.datetime.strptime(date_str, "%Y-%m-%dT%H:%M:%S")
message_length = len(message_text)
if name in user_hour_counts:
if sent_time.hour in user_hour_counts[name]:
user_hour_counts[name][sent_time.hour] += message_length
else:
user_hour_counts[name][sent_time.hour] = message_length
else:
user_hour_counts[name] = {sent_time.hour: message_length}
# 개별 사용자의 발신 시간대 그래프 그리기
for name, hour_counts in user_hour_counts.items():
hours = sorted(hour_counts.keys())
counts = [hour_counts[hour] for hour in hours]
plt.plot(hours, counts, label=name)
plt.xlabel("Hour", fontproperties=fontprop)
plt.ylabel("Message Length", fontproperties=fontprop)
plt.suptitle(group_name + " 메세지 전송 시각", fontsize=16, fontproperties=fontprop)
plt.legend(prop=fontprop)
plt.title(ChartTitle + " 발신 시간: 글자수 기준", fontproperties=fontprop)
# 결과 폴더가 없다면 생성
if not os.path.exists(result_folder):
os.makedirs(result_folder)
# 이미지로 저장
plt.savefig(result_folder + ChartTitle + " " + group_name + " 메세지 전송 시각(글자수 기준).png")
plt.show()
import json
import re
from collections import Counter
from wordcloud import WordCloud
import matplotlib.pyplot as plt
import matplotlib.font_manager as fm
import os
def run(font_path, group_name, result_folder):
start_date = input("YYYYMM: ")
if start_date == "all":
start_date = ""
ChartTitle = "모든 기간"
else:
start_year = start_date[:4]
start_month = start_date[4:]
ChartTitle = start_year + "년 " + start_month + "월"
# 입력 파일 경로
input_file = fr".\src\data{start_date}.json"
# 폰트 설정
fontprop = fm.FontProperties(fname=font_path)
# JSON 파일 읽기
with open(input_file, "r", encoding="utf-8") as f:
json_data = json.load(f)
# 사용자별 메시지 추출
user_messages = {}
for item in json_data:
name = item.get("name")
message_text = item.get("text")
if name and message_text:
if name in user_messages:
user_messages[name].append(message_text)
else:
user_messages[name] = [message_text]
# 특수 문자 및 제외할 단어 목록
special_chars = r"[^\w\s]"
exclude_words = ["type", "text", "link"]
# 유저별 가장 많이 사용하는 단어 추출
user_top_words = {}
for user, messages in user_messages.items():
words = []
for message in messages:
cleaned_message = re.sub(special_chars, "", str(message).lower())
words.extend(cleaned_message.split())
word_counts = Counter(words)
for word in exclude_words:
if word in word_counts:
del word_counts[word]
top_words = word_counts.most_common(100)
user_top_words[user] = top_words
# 워드 클라우드 생성 및 표시
num_users = len(user_top_words)
num_cols = 3 # 한 행에 그려질 그래프의 개수
num_rows = (num_users - 1) // num_cols + 1
fig, axs = plt.subplots(num_rows, num_cols, figsize=(12, 8))
fig.suptitle(ChartTitle + " " + group_name + ' 자주 하는 말(필터 OFF)(개인)', fontsize=16, fontproperties=fontprop)
for i, (user, top_words) in enumerate(user_top_words.items()):
wordcloud = WordCloud(
background_color="white",
font_path=font_path,
width=800,
height=600
).generate_from_frequencies(dict(top_words))
ax = axs[i // num_cols, i % num_cols]
ax.imshow(wordcloud, interpolation="bilinear")
ax.set_title(f"Word Cloud for {user}", fontproperties=fontprop)
ax.axis("off")
# 빈 자리에 그래프가 그려지지 않도록 설정
for i in range(len(user_top_words), num_rows * num_cols):
ax = axs[i // num_cols, i % num_cols]
ax.axis("off")
plt.tight_layout()
# 결과 폴더가 없다면 생성
if not os.path.exists(result_folder):
os.makedirs(result_folder)
# 이미지로 저장
plt.savefig(result_folder + ChartTitle + " " + group_name + ' 자주 하는 말(필터 OFF)(개인).png', bbox_inches='tight')
plt.show()
wordcloud 형태로 가장 많이 사용한 단어를 보여줍니다. 개인별로 보여주며 필터OFF라는 말은 조사 등을 그대로 포함했다는 의미입니다.
trending_words_no_filtered - 자주 쓰는 단어(필터 OFF)(개인)
7. trending_words_no_filtered2 - 자주 쓰는 단어(필터 OFF)(단체)
import json
import re
from collections import Counter
from wordcloud import WordCloud
import matplotlib.pyplot as plt
import matplotlib.font_manager as fm
import os
def run(font_path, group_name, result_folder):
start_date = input("YYYYMM: ")
if start_date == "all":
start_date = ""
ChartTitle = "모든 기간"
else:
start_year = start_date[:4]
start_month = start_date[4:]
ChartTitle = start_year + "년 " + start_month + "월"
# 입력 파일 경로
input_file = fr".\src\data{start_date}.json"
# 폰트 설정
fontprop = fm.FontProperties(fname=font_path)
# JSON 파일 읽기
with open(input_file, "r", encoding="utf-8") as f:
json_data = json.load(f)
# 메시지 추출
messages = []
for item in json_data:
message_text = item.get("text")
if message_text:
messages.append(message_text)
# 특수 문자 및 제외할 단어 목록
special_chars = r"[^\w\s]"
exclude_words = ["type", "text", "link"]
# 단어 빈도수 계산
words = []
for message in messages:
cleaned_message = re.sub(special_chars, "", str(message).lower())
words.extend(cleaned_message.split())
word_counts = Counter(words)
for word in exclude_words:
if word in word_counts:
del word_counts[word]
top_words = word_counts.most_common(100)
# 워드 클라우드 생성
wordcloud = WordCloud(
background_color="white",
font_path=font_path,
width=800,
height=600
).generate_from_frequencies(dict(top_words))
# 워드 클라우드 표시
plt.figure(figsize=(8, 6))
plt.imshow(wordcloud, interpolation="bilinear")
plt.suptitle(ChartTitle + " " + group_name + ' 자주 하는 말(필터 OFF)(단체)', fontsize=16, fontproperties=fontprop)
plt.axis("off")
plt.tight_layout()
# 결과 폴더가 없다면 생성
if not os.path.exists(result_folder):
os.makedirs(result_folder)
# 이미지로 저장
plt.savefig(result_folder + ChartTitle + " " + group_name + ' 자주 하는 말(필터 OFF)(단체).png', bbox_inches='tight')
plt.show()
wordcloud 형태로 가장 많이 사용한 단어를 보여줍니다. 단체를 기준으로 통계를 보여주며 필터OFF라는 말은 조사 등을 그대로 포함했다는 의미입니다.
trending_words_no_filtered2 - 자주 쓰는 단어(필터 OFF)(단체)
import json
from collections import Counter
from konlpy.tag import Hannanum
from wordcloud import WordCloud
import matplotlib.pyplot as plt
import matplotlib.font_manager as fm
import os
def run(font_path, group_name, result_folder):
start_date = input("YYYYMM: ")
if start_date == "all":
start_date = ""
ChartTitle = "모든 기간"
else:
start_year = start_date[:4]
start_month = start_date[4:]
ChartTitle = start_year + "년 " + start_month + "월"
# 입력 파일 경로
input_file = fr".\src\data{start_date}.json"
# 폰트 설정
fontprop = fm.FontProperties(fname=font_path)
# JSON 파일 읽기
with open(input_file, "r", encoding="utf-8") as f:
json_data = json.load(f)
# 사용자별 메시지 추출
user_messages = {}
for item in json_data:
name = item.get("name")
message_text = item.get("text")
if name and message_text:
if name in user_messages:
user_messages[name].append(message_text)
else:
user_messages[name] = [message_text]
# 특수 문자 및 제외할 단어 목록
special_chars = r"[^\w\s]"
exclude_words = ["type", "text", "link"]
# 형태소 분석기 초기화
hannanum = Hannanum()
# 유저별 가장 많이 사용하는 단어 추출
user_top_words = {}
for user, messages in user_messages.items():
words = []
for message in messages:
if isinstance(message, str):
try:
# 문자열 디코딩
decoded_message = message.decode('utf-8')
except AttributeError:
decoded_message = message
# 형태소 분석을 통해 명사만 추출
nouns = hannanum.nouns(decoded_message)
words.extend(nouns)
word_counts = Counter(words)
for word in exclude_words:
if word in word_counts:
del word_counts[word]
top_words = word_counts.most_common(100)
user_top_words[user] = top_words
# 워드 클라우드 생성 및 표시
num_users = len(user_top_words)
num_cols = 3 # 한 행에 그려질 그래프의 개수
num_rows = (num_users - 1) // num_cols + 1
fig, axs = plt.subplots(num_rows, num_cols, figsize=(12, 8))
fig.suptitle(ChartTitle + " " + group_name + ' 자주 하는 말(필터 ON)(개인)', fontsize=16, fontproperties=fontprop)
axs = axs.flatten()
for i, (user, top_words) in enumerate(user_top_words.items()):
if i < len(axs):
wordcloud = WordCloud(
background_color="white",
font_path=font_path,
width=800,
height=600
).generate_from_frequencies(dict(top_words))
ax = axs[i]
ax.imshow(wordcloud, interpolation="bilinear")
ax.set_title(f"Word Cloud for {user}", fontproperties=fontprop)
ax.axis("off")
else:
break
# 남는 빈 자리에 그래프가 그려지지 않도록 설정
for i in range(len(user_top_words), len(axs)):
ax = axs[i]
ax.axis("off")
plt.tight_layout()
# 결과 폴더가 없다면 생성
if not os.path.exists(result_folder):
os.makedirs(result_folder)
# 이미지로 저장
plt.savefig(result_folder + ChartTitle + " " + group_name + ' 자주 하는 말(필터 ON)(개인).png', bbox_inches='tight')
plt.show()
wordcloud 형태로 가장 많이 사용한 단어를 보여줍니다. 개인별로 보여주며 필터ON이라는 말은 조사 등을 거르고 난 뒤에 표현한다는 의미입니다.
import json
from collections import Counter
from konlpy.tag import Hannanum
from wordcloud import WordCloud
import matplotlib.pyplot as plt
import matplotlib.font_manager as fm
import os
def run(font_path, group_name, result_folder):
start_date = input("YYYYMM: ")
if start_date == "all":
start_date = ""
ChartTitle = "모든 기간"
else:
start_year = start_date[:4]
start_month = start_date[4:]
ChartTitle = start_year + "년 " + start_month + "월"
# 입력 파일 경로
input_file = fr".\src\data{start_date}.json"
# 폰트 설정
fontprop = fm.FontProperties(fname=font_path)
# JSON 파일 읽기
with open(input_file, "r", encoding="utf-8") as f:
json_data = json.load(f)
# 모든 사용자의 메시지 추출
all_messages = []
for item in json_data:
message_text = item.get("text")
if message_text:
all_messages.append(message_text)
# 특수 문자 및 제외할 단어 목록
special_chars = r"[^\w\s]"
exclude_words = ["type", "text", "link"]
# 형태소 분석기 초기화
hannanum = Hannanum()
# 모든 사용자의 가장 많이 사용하는 단어 추출
words = []
for message in all_messages:
if isinstance(message, str):
try:
# 문자열 디코딩
decoded_message = message.decode('utf-8')
except AttributeError:
decoded_message = message
# 형태소 분석을 통해 명사만 추출
nouns = hannanum.nouns(decoded_message)
words.extend(nouns)
word_counts = Counter(words)
for word in exclude_words:
if word in word_counts:
del word_counts[word]
top_words = word_counts.most_common(100)
# 워드 클라우드 생성 및 표시
wordcloud = WordCloud(
background_color="white",
font_path=font_path,
width=800,
height=600
).generate_from_frequencies(dict(top_words))
plt.imshow(wordcloud, interpolation="bilinear")
plt.suptitle(ChartTitle + " " + group_name + ' 자주 하는 말(필터 ON)(단체)', fontsize=16, fontproperties=fontprop)
plt.axis("off")
plt.tight_layout()
# 결과 폴더가 없다면 생성
if not os.path.exists(result_folder):
os.makedirs(result_folder)
# 이미지로 저장
plt.savefig(result_folder + ChartTitle + " " + group_name + ' 자주 하는 말(필터 ON)(단체).png', bbox_inches='tight')
plt.show()
wordcloud 형태로 가장 많이 사용한 단어를 보여줍니다. 단체를 기준으로 통계를 보여주며 필터ON이라는 말은 조사 등을 거르고 난 뒤에 표현한다는 의미입니다.


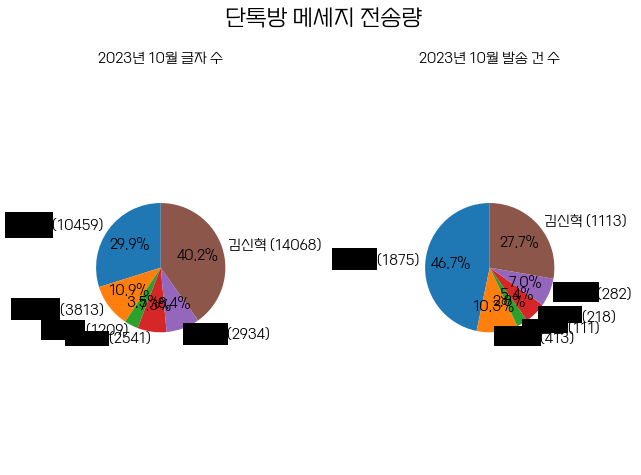





 📕 톡방 통계 프로그램
📕 톡방 통계 프로그램